One Page, Three Machines, Zero Surprises: The Maintenance Dashboard Every Plant Needs
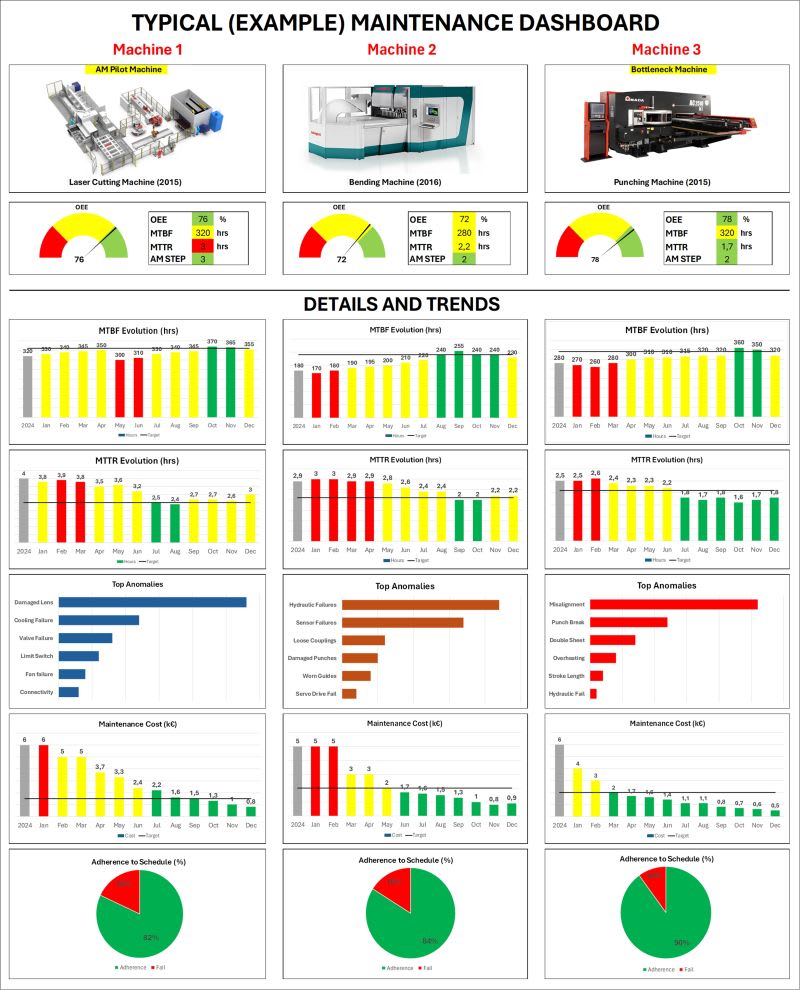
In many plants, maintenance is still managed through gut feeling, scattered files, or conversations at the coffee machine. When a critical machine stops, everyone suddenly realises how blind they actually are. That is why a simple, visual maintenance dashboard (like the example below for fictitious 3 machines) can be a real game changer. Here is what a good Maintenance Dashboard does for you: ✅ Connects reliability with business impact MTBF, MTTR, OEE and maintenance cost on one page show how technical problems translate into lost capacity, overtime and margin. It becomes much easier to argue for spare parts, upgrades or extra headcount when the data is visible and trend-based. ✅Makes problems obvious – every day Monthly trends of MTBF/MTTR, top 5 anomalies for each machine and adherence to schedule turn “we have many breakdowns” into a clear story: where they happen, how often and whether we are getting better or worse. People stop debating opinions and start attacking the real causes. ✅Drives discipline in preventive and autonomous maintenance When adherence to plan is on the dashboard, missed PMs and AM tasks are no longer invisible. Teams see immediately if they are protecting the bottleneck machine or running it to failure. That transparency builds a culture where planning and execution really matter. ✅Prioritises where to act first Instead of spreading resources thin, you quickly identify the pilot machine, the bottleneck and the “silent killers”. A focused Kaizen Study on the worst MTBF, or faster AM Progress on the top breakdown machine, becomes an obvious next step – not a guess. ✅ Creates common language between Production, Maintenance and Management With one page, everyone can align on the same facts: targets, gaps and actions. This is what turns daily meetings from status updates into true decision forums. You do not need a complex system to start. An Excel / Power BI dashboard with 3–5 core KPIs per machine, a simple Pareto of breakdowns and a cost trend is enough to change behaviour. If you are leading a factory, ask yourself: Can my team see, in 5 minutes, the “health status” of our critical machines? If not, a basic maintenance dashboard might be your fastest win this year.